Unicode规范化Bypass-CTF特殊题型
Unicode规范化会把本地编码系统中没有的特殊字符规范为一个本地编码系统中存在的,与这个特殊字符形状很相似的字符,有些CTF题目进行了十分暴力的过滤,可能就使用了这个考点,此时我们可以用这些字符绕过waf来构造payload,同时能达到相同的功能。
Unicode规范化Bypass
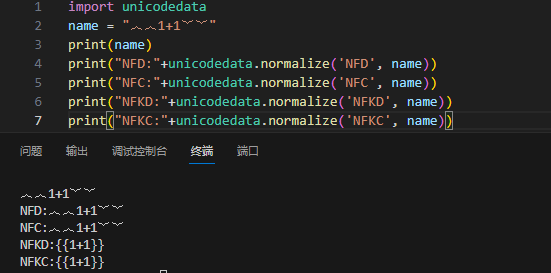
Unicode规范化在很早以前就被注意到可以用于生成出一些特殊关键字,但是没有被广泛介绍或者经常出现在CTF赛题中。例如︷︷1+1︸︸在NFKC/NFKD中会被解析为{{1+1}},用于绕过单花括号的直接过滤。XSS/SQLI题目也有类似的操作(注意只有进行了规范化的时候才有用)。
Unicode规范化简介
Unicode规范化是将多种表示形式的Unicode字符转换为统一形式的过程,有助于字符串比较和数据处理。
简单来说就是将一些相近的,及其罕见的特殊字符,变成本地编码中与这些特殊字符及其相近的字符。
Unicode的标准定义了四种规范化形式:
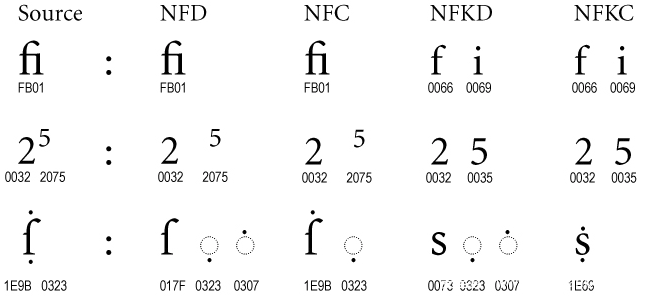
- NFD(Normalization Form D):将字符分解为基字符和组合字符的表示形式,并以正确的顺序组合它们。例如,字母“é”可能表示为一个基字符“e”和一个组合字符“´”,NFD标准化将其表示为“e´”。
- NFC(Normalization Form C):NFC标准化是NFD的组合形式,如果可能的话,它会将字符组合为一个等效的基字符。例如,NFC形式将以上面的例子中的“e´”标准化为单个字符“é”。
- NFKD(Normalization Form KD):NFKD标准化在NFD的基础上进一步规范化,通过替换某些字符来使字符串更加兼容。
- NFKC(Normalization Form KC):NFKC标准化是NFKD的组合形式,它会将字符组合为一个等效的基字符,同时进行替换以实现兼容性。
通俗一点:
NFD:规范化分解
NFKD:兼容性分解
NFC:规范化分解后再规范化组合
NFKC:兼容性分解后再规范化组合
NFKC和NFKD是主要利用点。
好用的网站
用几个实用的网站就可以解决所有利用场景:
轻松找到{的替代

XSS中比较可能派上用场的:
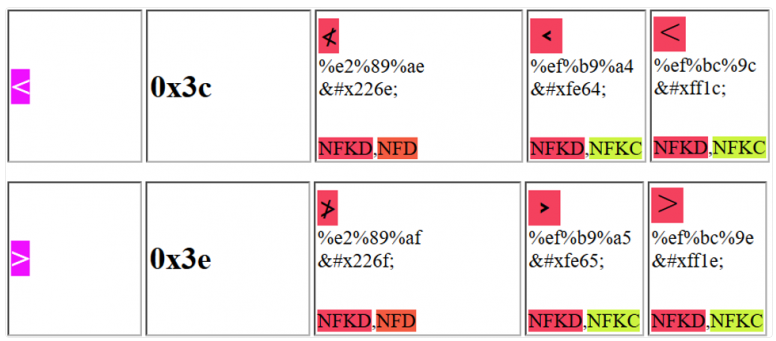
这个可以用来搜一些字符Unicode 符号表 - 所有 Unicode 字符及其代码都在一页上 (◕‿◕) SYMBL
利用流程
现在大部分框架如果不去特别的使用语句,实际上不会去规范化,因此往往不能派上用场,所以这多半只能作为后手尝试的时候使用。
可以尝试发送规范化“K”的U+0212A(%e2%84%aa),如果返回K,说明存在规范化,可以利用。
一些有趣的Unicode字符
o—%e1%b4%BCr—%e1%b4%bf1—%c2%b9=—%e2%81%BC/—%ef%bc%8f-—%ef%b9%a3#—%ef%b9%9f*—%ef%b9%a1'—%ef%bc%87"—%ef%bc%82|—%ef%bd%9c
还有上面提到的花括号、尖括号替代品。
这些字符在某些SQL注入可能派上用场:
1 | ' or 1=1-- - |
例如老版本的mssql原生就能使用规范化来构造payload,而在CTF中的各种题型里可能出题人需要主动进行规范化我们才能利用。